1. 出发点
最近朋友做竞品分析,抓取数据时无法获取到竞品的列表数据,但可以获取其单条新闻的请求。
因此,考虑由程序用模拟手机滑屏操作提交请求(该部分由他人负责开发),将请求包tcpdump为.pcap文件,再交由我进行报文解析,获取新闻返回的数据。
2. 技术点
wireshark打开pcap文件分析,只有分析确认出报文的特征,才能后续进行程序解析、过滤出靶向报文和目标信息。
- tcpdump 报文抓取
- Wireshark 报文分析
- Python scapy scapy_http 报文解析
- Python requests 报文请求
2.1 获取到HTTP Response回复内容
过滤条件:http and tcp.srcport==80 and http.content_type contains "json"
说明:过滤所有返回数据类型为json的http response报文,逐个过滤找到自己期待的数据,增加过滤条件定位至特定报文。
- 按照上述过滤条件的包,逐一筛选,找到目的报文
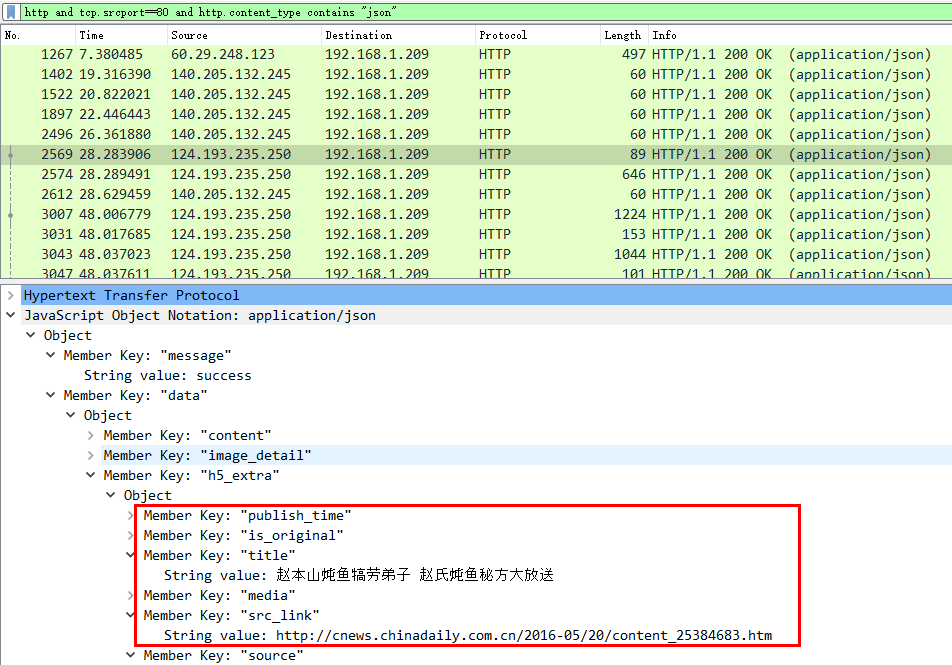
- 增加过滤条件,直接定位至目的报文
分析Http Response报文,查找其报文头部”唯一且区别其他报文的字段”,确定只有该报文具有X-Varnish字段的HTTP属性。
修改过滤条件:http and tcp.srcport==80 and http.content_type contains "json" and http.response.line contains "X-Varnish"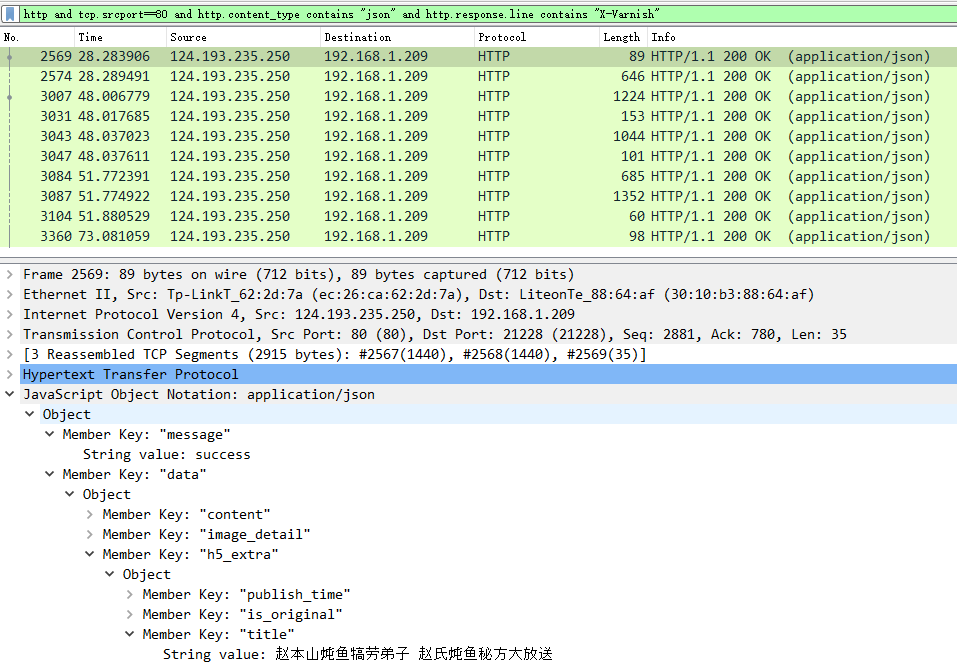
至此,定位出目标HTTP Response请求的报文。(注意:由于HTTP Response报文较大,分拆为多个TCP包传输,后文由此引发解析HTTP Response需要进行TCP报文重组的操作。)
2.2 获取到HTTP Request请求的url地址
根据已定位到的HTTP Response报文,选中Response报文,取消过滤条件,在Response前找HTTP且目的端口为80的报文。
定位出来的HTTP Request报文如下: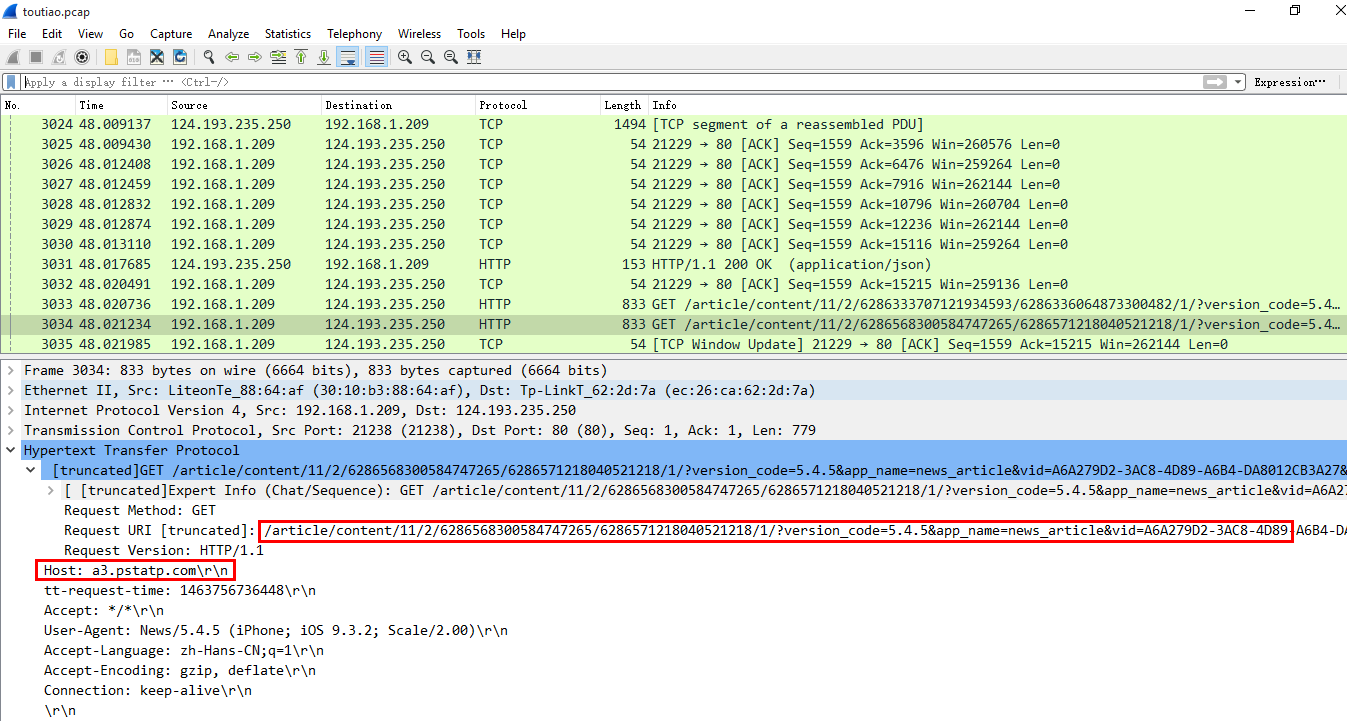
1
2GET /article/content/11/2/6286333707121934593/6286336064873300482/1/?version_code=5.4.5&app_name=news_article&vid=A6A279D2-3AC8-4D89-A6B4-DA8012CB3A27&device_id=14584054318&channel=App%20Store&resolution=750*1334&aid=13&ab_vers
Host: a3.pstatp.com\r\n
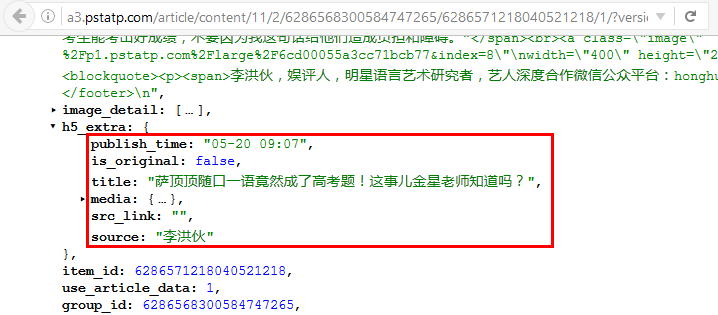
结合Request中的Host字段,则拼接出完整的Request url,直接浏览器访问或postman访问返回json数据如下:1
http://a3.pstatp.com/article/content/11/2/6286568300584747265/6286571218040521218/1/?version_code=5.4.5&app_name=news_article&vid=A6A279D2-3AC8-4D89-A6B4-DA8012CB3A27&device_id=14584054318&channel=App%20Store&resolution=750*1334&aid=13&ab_version=windowed-video-ios-0209-nowindow-1&ab_feature=z2&abflag=1&ab_group=z2&openudid=ab23f7e3c8eb996bc6258ada459da80220051279&idfv=A6A279D2-3AC8-4D89-A6B4-DA8012CB3A27&ac=WIFI&os_version=9.3.2&ssmix=a&device_platform=iphone&iid=4307772818&ab_client=a1,b1,b7,f1,f5,e1&device_type=iPhone8,1&idfa=699A6681-866D-4620-8614-D47B1B9067E4
2.3 完成HTTP Response回复内容统计
根据过滤条件中识别的所有Response报文,可手动统计出哪些回复信息。
PS: 但我们的目的肯定不是为了手动统计呀,继续往下看。
3. 可行方案
为了自动化获取到HTTP Response中信息,实现统计分析的目的,下述两种方法:
3.1 获取HTTP Request URL,调用requests或urllib2模块通过Python发起http请求,获取返回数据,解析
分析:该方式只是从pcap数据中获取http请求的url地址,再次模拟http请求,获取返回的json数据。
该方法未利用pcap文件中已存在的http response数据,而是重新请求并解析,一定程度上是二次抓取,效率减半。
利用Scapy、Scapy_http解析pcap文件,requests再次请求的Python实现代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35from scapy.all import *
import scapy_http.http as http
import requests
import json
pkts = rdpcap('test.pcap')
req_list = []
for pkt in pkts:
if TCP in pkt and pkt[TCP].fields['dport']==80 and pkt.haslayer(http.HTTPRequest):
http_header = pkt[http.HTTPRequest].fields
if 'Host' in http_header and '/article/content/' in http_header['Path']:
req_url = 'http://' + http_header['Host'] + http_header['Path']
req_list.append(req_url)
#print req_list
print str(len(req_list)) + ' toutiao request url achieved.'
f = open('result.log', 'w+')
record = 'title' + '\t' + 'source' + '\t' + 'src_link' + '\t' + 'publish_time' + '\t' + 'req_link' + '\n'
f.write(record)
for url in req_list:
res = requests.get(url).text
res = json.loads(res)
if 'data' not in res:
continue
if 'h5_extra' not in res['data']:
continue
h5_extra = res['data']['h5_extra']
title = h5_extra['title']
source = h5_extra['source']
src_link = h5_extra['src_link']
publish_time = h5_extra['publish_time']
record = title + '\t' + source + '\t' + src_link + '\t' + publish_time + '\t' + url + '\n'
f.write(record.encode('utf-8'))
f.close()
3.2 解析pcap数据中的http response数据,直接获取已返回的解析数据
最理想的解决方案:从pcap中解析已有的HTTP Response数据直接得到目标数据。
难点:HTTP Response报文被分割为多个TCP报文,需要进行TCP报文数据重组后才能还原出原始Response中携带数据。
TCP报文重组的思想:
- HTTP Request可能多个同时请求,则Response重组模型应是多线程的。
- 同一个Response的不同TCP包,需要按照Seq顺序重组。
- HTTP Response结束的标志位TCP报文中Flags字段为:0x018(PSH, ACK)。
- 将多个Response报文的TCP负载部分内容放在一起,gzip解压,可得到json数据。
PS: 上述过程仅为思路,未实现和验证。
4. 结论
- scapy/scapy_http读取解析.pcap文件的效率还可以,但过滤条件不太灵活且官网文档不全。
- TCP报文重组未找到开源解决方案,本文给出的实现思路也未验证。
- 若请求采用https方式,上述方法不可行,请另寻它法。
参考文献
- Python Scapy
- Python Scapy_http
- 关于HTTP请求报文的分片分析
- TCP的状态 (SYN, FIN, ACK, PSH, RST, URG)
- 用python实现wireshark的follow tcp stream功能
- TCP Flags: PSH and URG
- Extracting URLs from network traffic in just 9 Python lines with Scapy-HTTP
- Python—HTTP处理Gzip压缩数据
- Wireshark CaptureFilters
- Python Scapy实现自动HTTP流量分析嗅探
- TCP数据包重组实现分析