近期开始关注房产,链家官网有两周前的成交数据可供参考。
通过Python+requests+re+beautifulsoup4进行网页抓取、内容解析。
http请求
requests库进行http请求,要考虑的是编码问题,requests通过encoding设置能友好处理。1
2
3
4
5
6
7
8headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36',
'Refer': 'http://bj.lianjia.com/chengjiao/',
'Cookie': 'xxxxxx'
}
r = requests.get(url, headers = headers)
r.encoding = 'utf-8' # 设置编码
html = r.content
数据库表结构
1 | CREATE TABLE `chengjiao` ( |
html解析
beautifulsoup对html解析相比htmlparse更智能便捷。
- 通过css选择器定位元素:soup.select(‘.classname > li’)选择.classname累下的li节点
- beautifulsoup中Tag节点逐级选择,注意在元素有子节点时string无法获取内容,需要通过逐级定位元素后才能通过string获取内容
- contents获取所有子节点,排查位置时比较便捷
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29soup = BeautifulSoup(html, 'lxml')
li_list = soup.select('.listContent > li')
for li in li_list:
try:
img_origin = li.a.img['data-original'] # img_origin: 高清图片
href = li.select('div[class="title"]')[0].a['href'] # href: 详情页url
lj_id = re.search(r'/(\d*).html', href).group(1) # lianjia id: 链家id
title = li.select('div[class="title"]')[0].a.string # title: 标题
# 对title切割为:小区(community), 户型(layout), 面积(area)
title_arr = title.split(' ')
community = title_arr[0]
layout = title_arr[1]
area = title_arr[2]
deal_date = li.select('div[class="dealDate"]')[0].string # dealDate: 成交时间
total_price = li.select('div[class="totalPrice"]')[0].span.string # totalPrice : 成交价格
position_icon = li.select('div[class="positionInfo"]')[0].contents[1] # positionInfo: 楼层位置及年代
floor = position_icon.split(' ')[0] # 楼层
age = position_icon.split(' ')[1] # 年限
source = li.select('div[class="source"]')[0].string # source: 交易来源
unit_price = li.select('div[class="unitPrice"]')[0].span.string # unitPrice: 单价(元/平米)
session = saveChengjiaoToDB()
sql = ("'insert into chengjiao(lj_id, img_origin, href, title, community, layout, area,",
"deal_date, total_price, position_icon, floor, age, source, unit_price) values('")
sql += lj_id + ',"' + img_origin + '","' + href + '","' + title + '","' + community + '","' + layout + '","' + area + '","' + deal_date + '","' + total_price + '","' + position_icon + '","' + floor + '","' + age + '","' + source + '","' + unit_price + '"'
sql += ')'
session.execute(sql)
session.commit()
except BaseException, e:
print 'ERROR: ' + str(e) + ', URL: ' + url
存表后的数据: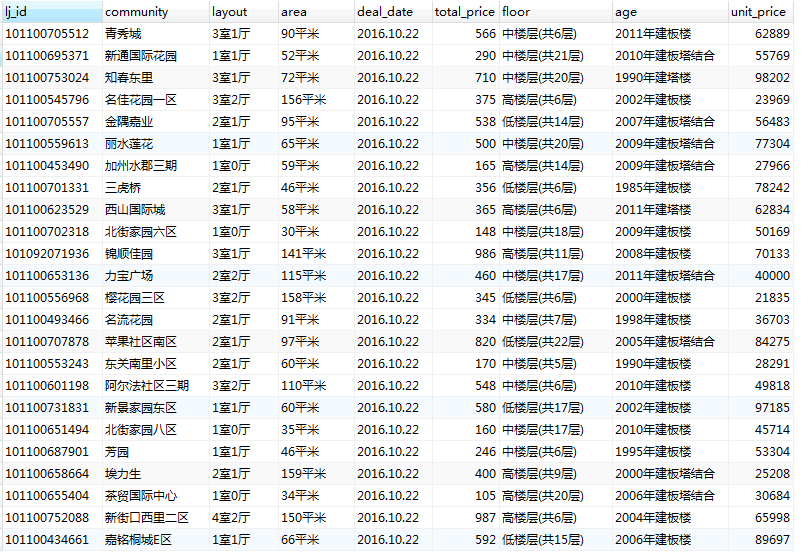
总结
这套逻辑比较粗糙,纯粹是无聊+熟悉python,如果生产环境建议采用scrapy
最后如果关注房产数据的话,可访问北京房市儿这个网站,走势比较丰富。
其实实现里又增加了根据lj_id去重,每天自动化任务自动抓取,实现收集一定时间内北京房地产成交数据。
PS: 链家数据可靠性未知,仅供参考。脚本抓取仅供技术分享,误滥用,毕竟频繁抓取对服务器的压力给RD同学也是伤。