团队内分享PHP7源码,重读代码过程中发现其中不少优秀设计之处,整理一篇其源码中的优雅设计。
阅读要求:对PHP7源码实现有一定了解,具备一定的源码分析能力
推荐几篇优秀的文章,建议先行阅读:
- Array/HashTable实现,推荐阅读 Julien Pauli-PHP 7 Arrays : HashTables
- 鸟哥Laruence的slide:The secret of PHP7’s Performance
Array如何保证有序
问题:在PHP中Array数组是通过HashTable哈希来实现,但由于Hash的特性是高效访问、但数据无序,因此面临数组遍历时顺序的问题?
先来看看数组Array的实现
数组的两个重要结构体:
Bucket:单个元素的存储单元_zend_array别名HashTable:数组的上层封装1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29typedef struct _Bucket {
zval val;
zend_ulong h; /* hash value (or numeric index) */
zend_string *key; /* string key or NULL for numerics */
} Bucket;
typedef struct _zend_array HashTable;
struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar reserve)
} v;
uint32_t flags;
} u;
uint32_t nTableMask;
Bucket *arData;
uint32_t nNumUsed;
uint32_t nNumOfElements;
uint32_t nTableSize;
uint32_t nInternalPointer;
zend_long nNextFreeElement;
dtor_func_t pDestructor;
};
老生常谈_zend_array:
gc:引用计数u:联合体flags或v标志位nTableMask:掩码, = -nTableSize*arData:指向数据元素存储Bucket地址nNumUsed:数组内已使用空间数量(unset元素后nNumUsed不变,nNumOfElements减少)nNumOfElements:数组内有效元素个数nTableSize:数组空间开辟大小nInternalPointer:待补充nNextFreeElement:下一个可用元素位置pDestructor:析构时处理
HashTable巧妙之处:nTableMask
nTableMask = -nTableSize:为什么同样一个nTableSize数值,额外用nTableMask冗余一份呢?- 通过位运算计算nIndex
nIndex = p->h | ht->nTableMask h是key进行hash计算后的哈希值,与nTableMask(补码表示,nTableSize反码+1)或运算,取值范围[0, nTableSize-1]- 实现效果与
nIndex = p->h % ht->nTableSize相同,但位或运算效率比模运算高很多 - 空间 VS 时间 效率的博弈,这里冗余一个字段,大大提升频繁
nIndex计算的效率
- 通过位运算计算nIndex
HashTable巧妙之处:nNumUsed和nNumOfElemets
nNumUsed和nNumOfElemets为何区分开?- 释放中间元素时不做内存处理,保证高效,仅标记元素
p->val->u1.v.type=IS_UNDEF - 在
resize()或rehash()时将已删除的IS_UNDEF元素进行内存重整
- 释放中间元素时不做内存处理,保证高效,仅标记元素
Array巧妙之处:arData、nIndex、idx
- Array底层使用HashTable存储,如何保证插入数组元素的有序性?
- 先重点看下arData指向的Bucket内部结构如下:
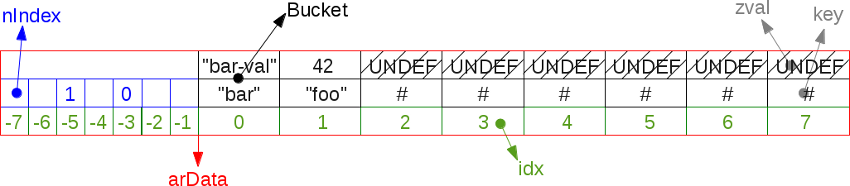
- 上图例子数据写入过程:
nTableSize=8,nTableMask = -nTableSize = -8- 数组首次写入元素
$array['bar] = 'bar-val'时,h为bar经过Time33算法计算后的数值,nIndex = h | nTableMask = -3 idx=nNumUsed++、arData[nIdex] = idx,从而写入映射表arData[-3] = 0,数据写入arData[idx]=Bucket{key,h,val}也就是arData[0]={'bar',hash(bar),'bar-var'}- 相同的,插入
$array['foo'] = 42时,写入映射表arData[-5]=1,数据写入arData[idx]=Bucket{key,h,val}也就是arData[1]={'foo',hash(foo),42} 
arData指向区域包含两部分:hash映射表和数据存储Buckets,后者Buckets为数据存储区。如直接hash取模的方式存储(散列值跳跃且分散),则遍历时无法保证顺序,因此衍生出通过hash映射表来实现的方式arData指向Buckets存储区的起始位置,而hash映射表在其负值索引位置上,nIndex为负值,通过数组的负值索引快速访问arData[nIndex]值- 具体来说,根据
nNumUsed确定首个可用Buckets索引地址idx,继而计算nIndex(nIndex = h | nTableMask),将数据在Buckets区的存储索引idx保存到映射表:arData[nIndex] = idx - 索引查找时,按照
h->nIndex->idx的顺序查找数据,几乎是O(1)复杂度的 - 顺序遍历时,按照Buckets区逐一遍历即使插入时顺序
- 巧妙的,这里将映射表和数据区连续内存空间存储,且nIndex通过
h|nTableMask的方式快速计算获得,极大保证计算效率;连续分配,释放、扩容时都是简单高效的处理方式
- 先重点看下arData指向的Bucket内部结构如下:
最终数组的存储结构:(图片来源鸟哥分享slide)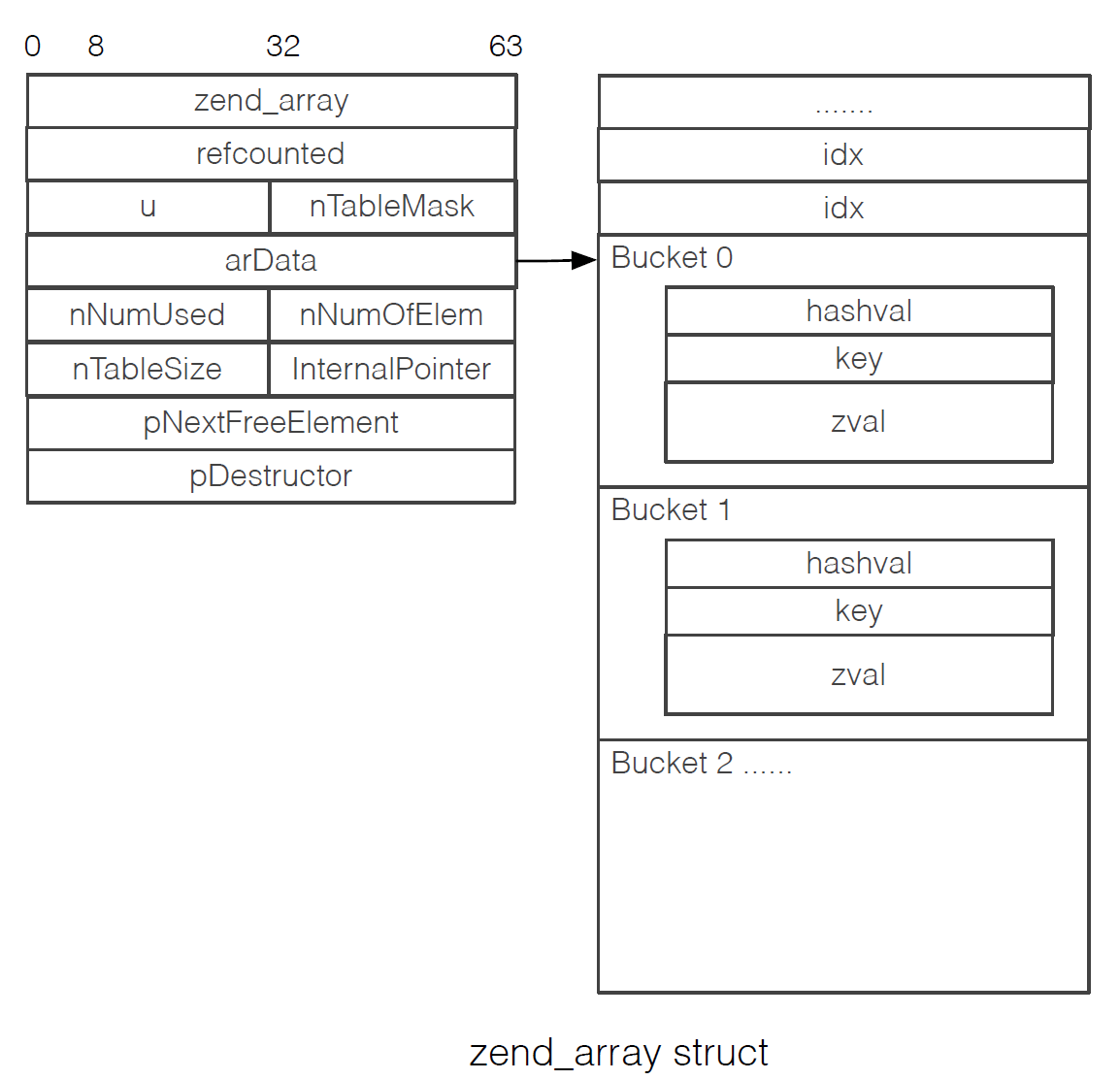
zend_string中变长数组
zend_string结构体定义:1
2
3
4
5
6struct _zend_string {
zend_refcounted_h gc;
zend_ulong h; /* hash value */
size_t len;
char val[1];
};
gc:引用计数h:字符串对应的hash值len:字符串长度val[1]:变长数组,实际字符串存储区域
zend_string巧妙之处:val[1]
- 变长数组(Variable-length array)是在ISO C99之后才支持的特性,使用此特性需要编译器支持C99标准。
- 零长数组是GNU C版本编译器支持,并引导C99最终支持变长数组的经典案例,但不同版本实现的编译器可能不支持零长数组。
- 在PHP7源码中为了兼容不同版本编译器、利用变长数组特性,使用
val[1]来实现固定头部的可变对象的存储形式。
后续补充:
巧妙之处:IS_UNDEF
TODO:删除时设置为IS_UNDEF,在需要时统一进行内存整理提高单次操作性能。